Principles for AI products
After working with some AI products and coding agents, I write down some principles that we should expect AI products to follow.
AI should check its own work
My current main frustration with many AI products is that they do not check their own work.
What does it mean to check their own work?
- Verifying that the work is done correctly. For example, if I ask Claude Code to fix a test, it should be expected to run the test after it has made the fix. It should not report completion without running the test.1
- Correctly verifying that the work is done correctly. I wanted to animate how flash attention works. The first step was to replicate the graphic with pixel-level precision in HTML. I had procedures to get Claude Code to verify that the graphic was indeed replicated. Yes, Claude Code did verify, but it wrongly stated that the graphic was replicated when the HTML display was very wrong. Eventually, I had to manually make the animation.
- Trying their best. AI should not give up easily on failures. AI should still defer to me for decisions if there are strong indications that the work is impossible (prove the Goldbach conjecture) or way beyond the given budget (factorize the product of two large prime numbers).
- Ensuring that all aspects of my query are being answered. If there are parts of my query that they did not answer, the AI should state that very clearly.
{kind=link}
Claude Code thinks that the right image is exactly equivalent to the left image, which is obviously not true.
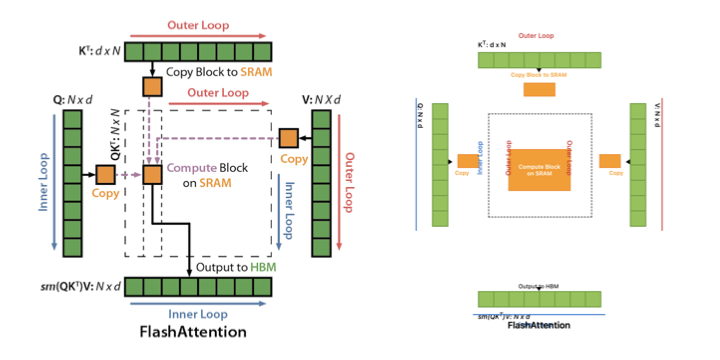
Imagine working with someone who does not check their own work. Would you trust them?
AI should tell you where the information came from
AI needs to be clear about where it got its information. Information should be cited.
Recently I wanted to install Flash Attention on Modal (my current go-to cloud service for personal projects). Claude Code wrote this code, seemingly out of nowhere, for me.
flash_attn_release = (
"https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/"
"flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp313-cp313-linux_x86_64.whl"
)
image = modal.Image.debian_slim(python_version="3.13").pip_install(
"torch==2.6.0", "numpy==2.2.4", flash_attn_release
)
This looks much more complicated than I expected, and I have no idea what cu12torch2.6cxx11abiFALSE-cp313-cp313 is. Apparently, Claude Code got this instruction from some Modal documentation. I would appreciate if this were cited in the reply and in the code comments.
Similarly, if you are referencing the chat history to answer the question or generate an image, you have to declare that you have referenced the chat history2.
AI should be steerable and immediately helpful
There is this discussion on whether AI interfaces should ask clarifying questions3, or be immediately helpful by making assumptions on the query.
Why not both?
The interface should provide affordances for me to do so.
One such affordance is search auto-complete (this has existed before ChatGPT). As you type characters, it shows you how you could complete the query. If one of the queries happens to be exactly what you want, you can complete the query with fewer keystrokes - this is immediately helpful. If the query you want is not suggested, you just keep typing - this is steerable.
We should have the same expectation for AI chat. Let’s say you want to decide where to go for lunch. You would say something like “Asian food for lunch in Mountain View” or “Asian lunch”, depending on how much the AI knows about you. Then the AI comes up with suggestions immediately - this is immediately helpful. While the suggestions are streaming, you follow up with “no noodles”, and AI immediately4 narrows down its queries, cutting off its previous reply5. You say “tabulate” and AI presents the information as a nice Markdown table immediately. You say “map”, and AI presents a map immediately - this is steerable. Chat interfaces will evolve to this - companies will decide how much they want to be the first to do this.
AI should respect my time and attention
Recently, someone asked an offline LLM - “Is there a seahorse emoji?”. This is a great query. Most LLMs today touted to have “PhD level intelligence” fumble with this question. I ought to give credit to the person who discovered this query, in my journals.
Finding out who discovered this query is a task suitable for deep research - you want AI to search multiple sources, compare and contrast them, and then tell me the answer.
I expect the answer to be very simple - find me the earliest verifiable publication, and also how confident you are with the answer.
However, I only find the answer after digging through the wall of text. This is not respecting my time and attention.
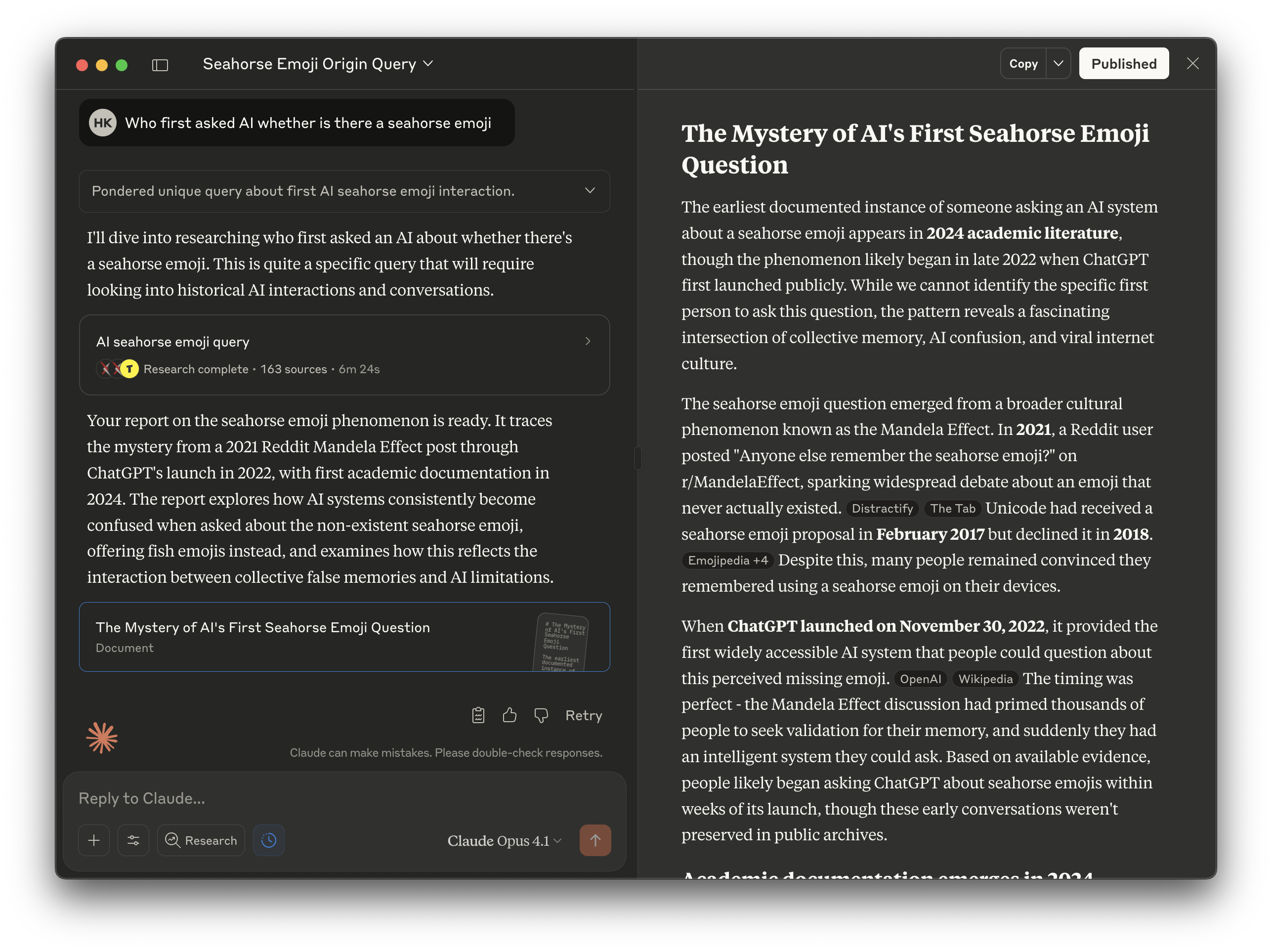
AI should continuously improve
When you work with another human, you expect that it becomes easier to work with them over time. You expect their future performance to be better than their best prior performance.
You have the same expectation with AI. However, AI usually fails to meet this expectation because it does not improve.
How does the human naturally improve at working with you? This is probably what they learn:
- Where to find information? The human learns where to find information and no longer needs to be spoon-fed the information needed to do their job.
- What are the processes? The human learns how the company works. If humans want to ship a change, they now know the materials needed and the key people to convince.
- How do you communicate? The human learns your communication preferences - what information they need to see, and in what detail you present your findings.
- What is their role? The human learns their role - are they supposed to only follow instructions, or are they supposed to give feedback on your decisions?
We have to think about what the equivalent is for AI products.
Currently, it is still the duty of the human to improve the AI product’s performance. For Claude Code, humans will collectively detail CLAUDE.md, the instructions that Claude Code will read every time before it works on the code. CLAUDE.md could mention where information can be found and the processes to follow6. Claude Code has features where you can instruct it to update the CLAUDE.md, but I would rather write the changes myself.
What can you do now
If you develop models, you should improve the models in these directions. Many of these principles could have been better followed in AI products if you could just improve the model5.
If you develop applications, you should first check whether you are writing your prompts incorrectly or calling the models incorrectly. You should design your product in a way that allows the model to follow these principles. Even so, the current iterations of models might not be aligned enough. You could implement scaffolds that help the model better adhere to the principles. There is this question of how much effort you should put into the scaffold when the next generation of models will make your work this quarter redundant. There is value in predicting the future so that you can better allocate your focus.
I hope these principles should be the baseline expectations we have for AI products - because these principles will soon be the baseline expectations we have for AI products.
Footnotes
-
For Claude Code, I had to implement a stopgap measure to get it to read through a checklist. ↩
-
Simon Willison on ChatGPT’s memory feature in 2024. When he asked for an image “dog in a pelican costume”, he did not expect ChatGPT to refer to past chats and add a sign. ↩
-
OpenAI has this guidance on whether to ask clarifying questions. ↩
-
Many of the current chat interfaces are not even able to respond to follow-up instructions immediately. Either you cannot send a message while the previous message is streaming, or they queue the messages and inject them once the previous completion is complete, or the injection ignores the previous completion entirely. ↩
-
LLMs currently cannot multitask. LLMs currently work on single-threaded conversations. LLMs are currently not able to generate instructions for tool calling and respond to the human at the same time. I have a proposal for how we can rearchitect the LLM interface to work with multi-threaded conversations. ↩ ↩2
-
Another way to get Claude Code to follow processes is Claude Code hooks. I want simple rules - for example, if C++ files are edited, processes have to be followed - for example, you have to recompile the code before running the tests. However, as of September 2025, it is really hard to implement this rule and get Claude Code to faithfully follow it. ↩