I did "autoresearch" in a hackathon and won some GPU credits
There was an Autoresearch Systems Hackathon on May 30, 2026.
I won third place. The prize was $1,000 of Modal credits, $1,000 of ChatGPT credits, and 6 months of ChatGPT Pro.
I was admitted to the hackathon two days before the hackathon - I signed up three days before.
At that time I was already working on setting up my environment for ARC-AGI-3.
This is what I already had
- Some neural network that was inspired by AlphaGo
- Ideal gameplay traces
- Submission pipeline
I made some preparations before the hackathon
- I made some “modified games”. “Modified games” have the same engine logic as the games published by the ARC Foundation, but with slight modifications. For example, for the “original game” ar25, the shapes of the objects were made different.
- I generated the ideal gameplay traces on the modified games.
Autoresearch objective
I only started the autoresearch system halfway through the hackathon. The purpose of the autoresearch system is to figure out a good neural network model that is able to predict actions.
The model will need to
- predict which of the six actions (up, down, left, right, space, click) will be taken
- predict which color (among the colors present in the frame) will be chosen
- predict which coordinate (among the coordinates of the chosen color) will be clicked
The loss function is cross entropy. Color and coordinate logits will be masked if irrelevant. The loss for color and coordinate will not be computed if irrelevant.
Each action taken by the agent is transformed into a 384 x 64 x 64 matrix for input. I defined the transformation.
The training data is the ideal gameplay actions on the modified games. The validation data is the ideal gameplay actions on the original games.
I set up a system for the agent (Claude Code) to experiment with different model architectures that minimize the validation loss.
Performance
Each training loop takes between 5 and 30 minutes. The free tier of Modal allows you to use 10 GPUs at once.
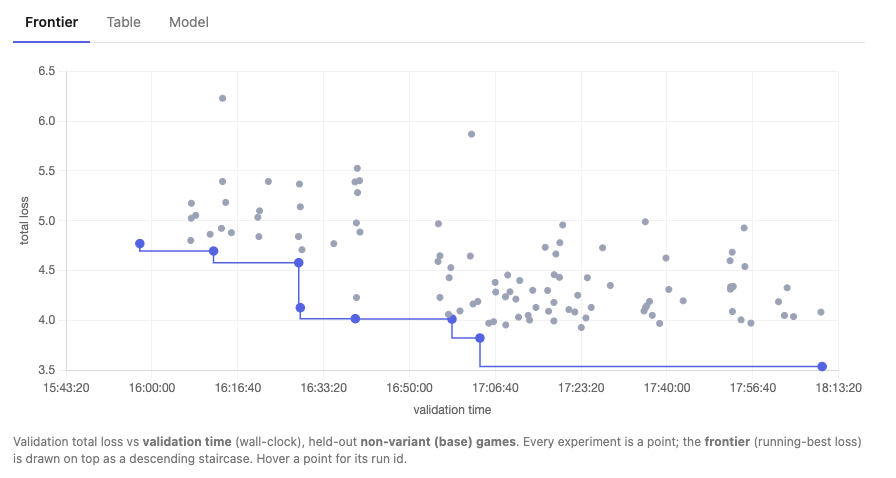
This is the “autoresearch” graph. The agent started with a model architecture with a validation loss of around 4.5, and eventually found a model architecture with a validation loss of 3.5.
For the model that achieved a validation loss of 3.5, the model initialized with a training loss of 12.0 and somewhat converged to a training loss of 2.0.
However, when playing even the games that it has trained on, I have no evidence that the trained model is performing better than a model that simply takes random actions.
Things I remembered I had to intentionally design
The only job of the autoresearch agent is to figure out the model architecture. I want the agent to assume that the data is fixed, and focus on optimizing the model architecture. I decided that I would be the one to transform the game state into the model input (384 x 64 x 64).
Every model tested should be a standalone file that should not be modified after testing. Initially I discovered that the agent modified the model architecture code after testing - this is bad because it makes it very difficult to understand exactly which model architecture produced a given result.
Validation loss should only be calculated at the end. I want the training to be done quickly so that the agent can iterate on model architecture. Maybe I could instead set up a system to export the current model and calculate the validation loss at every quarter of the data without blocking the training process.
These are some things I learnt
Data is important. I spent more time on the data than on the autoresearch system, and I still think I need to spend more time on the data. I still do not have the confidence that I am curve-fitting on a reasonable dataset. I also suspect that I might be somewhat leaking the targets in the input.
Data shuffling is hard. You want your data shuffled so that you can trust that the training loss has decreased. You cannot load all the data in memory and generate the shuffle. A simple filesystem where you have one file per datapoint would not scale. This is something I must consider when I work on something similar.
Validation score is a distribution. There was a model variant that hit 3.5 validation loss, and for a while, other model variants could not beat the score. When the agent decided to rerun the training for that model variant, the validation loss was 3.9. This means that scores on the frontier can be noisy. One remedy is to encourage experiments to be repeated and frontier scores updated.
Validation loss does not really mean anything. I used the trained model to play the games that it trained on, and its performance is bad. It could not clear even the first level. Even if I were to scale the amount of data, I do not think the model can learn to play a quarter of the games it has trained on. (Note that for the ARC-AGI leaderboard, the model will need to solve games it has not seen.)
Code quality is important. The code I wrote in a short time has a lot of hacks. For example, I need to decide whether I should treat each “modified game” the same as an “original game” in my system. I also have to ensure that my system works with multiple external abstractions - ARC SDK, Kaggle notebooks. I think I will be cleaning up most of the autoresearch code in the main repository.
Learning needs to be intentional. The autoresearch system treats each training cycle as a black box. The agent modifies the architecture, runs the training script, and reports the loss. It does not attempt to understand why one model architecture is better than another. Optimizing merely for the validation loss may be optimal if you want to produce immediate results, and this is the correct decision in a hackathon. However, neither the agent nor I am learning anything, and we are very far from solving the main task of training a model to play games that it has seen in training.